13.2.11 分组和组函数 组函数 也就是前面提到的多行函数 ,组函数将一组记录作为整体计算,每组记录返回一个结果,而不是每条记录返回一个结果 。常用的组函数有如下5个。
avg([distinct|all]表达式):计算多行表达式的平均值 ,其中,表达式可以是变量、常量或数据列,但其数据类型必须是数值型。还可以在变量、列前使用distinct或all关键字,如果使用distinct,则表明不计算重复值;all用和不用的效果完全一样,表明需要计算重复值。count({*|[distinct|all]表达式}):计算多行表达式的总条数 ,其中,表达式可以是变量、常量或数据列,其数据类型可以是任意类型;用星号(*)表示统计该表内的记录行数;distinct表示不计算重复值。max(表达式):计算多行表达式的最大值 ,其中表达式可以是变量、常量或数据列,其数据类型可以是任意类型。min(表达式):计算多行表达式的最小值 ,其中表达式可以是变量、常量或数据列,其数据类型可以是任意类型。sum([distinct|all]表达式):计算多行表达式的总和 ,其中,表达式可以是变量、常量或数据列,但其数据类型必须是数值型;distinct表示不计算重复值。
实例 sum函数 统计某列的总和 统计所有student_id的总和
1 2 select sum (student_id)from student_table;
计算结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 mysql> select * from student_table; +------------+--------------+--------------+ | student_id | student_name | java_teacher | +------------+--------------+--------------+ | 1 | 张三 | 1 | | 2 | 张三 | 1 | | 3 | 李四 | 1 | | 4 | 王五 | 2 | | 5 | _王五 | 2 | | 6 | NULL | 2 | | 7 | 赵六 | 3 | +------------+--------------+--------------+ 7 rows in set mysql> select sum(student_id) from student_table; +-----------------+ | sum(student_id) | +-----------------+ | 28 | +-----------------+ 1 row in set
每行都加上一个常数 1 2 select sum (20 )from student_table;
计算结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 mysql> select * from student_table; +------------+--------------+--------------+ | student_id | student_name | java_teacher | +------------+--------------+--------------+ | 1 | 张三 | 1 | | 2 | 张三 | 1 | | 3 | 李四 | 1 | | 4 | 王五 | 2 | | 5 | _王五 | 2 | | 6 | NULL | 2 | | 7 | 赵六 | 3 | +------------+--------------+--------------+ 7 rows in set mysql> select sum(20 ) from student_table; +---------+ | sum(20 ) | +---------+ | 140 | +---------+ 1 row in set
不累加值相同的行 因为sum里的表达式是常量34,所以每行的值都相同使用 distinct强制不计算重复值,所以下面计算结果为34
1 2 select sum (distinct 34 )from student_table;
计算结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 mysql> select * from student_table; +------------+--------------+--------------+ | student_id | student_name | java_teacher | +------------+--------------+--------------+ | 1 | 张三 | 1 | | 2 | 张三 | 1 | | 3 | 李四 | 1 | | 4 | 王五 | 2 | | 5 | _王五 | 2 | | 6 | NULL | 2 | | 7 | 赵六 | 3 | +------------+--------------+--------------+ 7 rows in set mysql> select sum(distinct 34 ) from student_table; +------------------+ | sum(distinct 34 ) | +------------------+ | 34 | +------------------+ 1 row in set
max函数 选出student_table表中student_id最大的值
1 2 select max (student_id)from student_table;
计算结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 mysql> select * from student_table; +------------+--------------+--------------+ | student_id | student_name | java_teacher | +------------+--------------+--------------+ | 1 | 张三 | 1 | | 2 | 张三 | 1 | | 3 | 李四 | 1 | | 4 | 王五 | 2 | | 5 | _王五 | 2 | | 6 | NULL | 2 | | 7 | 赵六 | 3 | +------------+--------------+--------------+ 7 rows in set mysql> select max(student_id) from student_table; +-----------------+ | max(student_id) | +-----------------+ | 7 | +-----------------+ 1 row in set
min函数 选出teacher_table表中teacher_id最小的值
1 2 select min (teacher_id)from teacher_table;
计算结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 mysql> select * from student_table; +------------+--------------+--------------+ | student_id | student_name | java_teacher | +------------+--------------+--------------+ | 1 | 张三 | 1 | | 2 | 张三 | 1 | | 3 | 李四 | 1 | | 4 | 王五 | 2 | | 5 | _王五 | 2 | | 6 | NULL | 2 | | 7 | 赵六 | 3 | +------------+--------------+--------------+ 7 rows in set mysql> select min(teacher_id) from teacher_table; +-----------------+ | min(teacher_id) | +-----------------+ | 1 | +-----------------+ 1 row in set
count方法 使用count统计记录行数时,null不会被计算在内
1 2 select count (student_name)from student_table;
统计结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 mysql> select * from student_table; +------------+--------------+--------------+ | student_id | student_name | java_teacher | +------------+--------------+--------------+ | 1 | 张三 | 1 | | 2 | 张三 | 1 | | 3 | 李四 | 1 | | 4 | 王五 | 2 | | 5 | _王五 | 2 | | 6 | NULL | 2 | | 7 | 赵六 | 3 | +------------+--------------+--------------+ 7 rows in set mysql> select count(student_name) from student_table; +---------------------+ | count(student_name) | +---------------------+ | 6 | +---------------------+ 1 row in set
avg方法 对于可能出现null的列,可以使用ifnull函数来处理该列。java_teacher列所有记录的平均值
1 2 select avg (ifnull (java_teacher,0 ))from student_table;
计算结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 mysql> select * from student_table; +------------+--------------+--------------+ | student_id | student_name | java_teacher | +------------+--------------+--------------+ | 1 | 张三 | 1 | | 2 | 张三 | 1 | | 3 | 李四 | 1 | | 4 | 王五 | 2 | | 5 | _王五 | 2 | | 6 | NULL | 2 | | 7 | 赵六 | 3 | +------------+--------------+--------------+ 7 rows in set mysql> select avg(ifnull(java_teacher,0 )) from student_table; +-----------------------------+ | avg(ifnull(java_teacher,0 )) | +-----------------------------+ | 1 .7143 | +-----------------------------+ 1 row in set
值得指出的是,distinct和*不能同时使用,如下SQL语句有错误。
1 2 select count (distinct *)from student_table;
错误:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 mysql> select * from student_table; +------------+--------------+--------------+ | student_id | student_name | java_teacher | +------------+--------------+--------------+ | 1 | 张三 | 1 | | 2 | 张三 | 1 | | 3 | 李四 | 1 | | 4 | 王五 | 2 | | 5 | _王五 | 2 | | 6 | NULL | 2 | | 7 | 赵六 | 3 | +------------+--------------+--------------+ 7 rows in set mysql> select count(distinct *) from student_table; 1064 - You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '*)from student_table' at line 1
分组的情况 在默认情况下,组函数会把所有记录当成一组,为了对记录进行显式分组,可以在select语句后使用group by子句,group by子句后通常跟一个或多个列名,表明查询结果根据一列或多列进行分组——当一列或多列组合的值完全相同时,系统会把这些记录当成一组 。如下SQL语句所示:
根据某一列进行分组 count(*)将会对每组得到一个结果:
1 2 3 select java_teacher,count (*)from student_tablegroup by java_teacher;
查询结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 mysql> select * from student_table; +------------+--------------+--------------+ | student_id | student_name | java_teacher | +------------+--------------+--------------+ | 1 | 张三 | 1 | | 2 | 张三 | 1 | | 3 | 李四 | 1 | | 4 | 王五 | 2 | | 5 | _王五 | 2 | | 6 | NULL | 2 | | 7 | 赵六 | 3 | +------------+--------------+--------------+ 7 rows in set mysql> select java_teacher,count(*) from student_table group by java_teacher; +--------------+----------+ | java_teacher | count(*) | +--------------+----------+ | 1 | 3 | | 2 | 3 | | 3 | 1 | +--------------+----------+ 3 rows in set
根据多列分组 如果对多列进行分组,则要求多列的值完全相同才会被当成一组 。如下SQL语句所示:
1 2 3 4 select student_name,java_teacher,count (*)from student_tablegroup by java_teacher,student_name;
查询结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 mysql> select * from student_table; +------------+--------------+--------------+ | student_id | student_name | java_teacher | +------------+--------------+--------------+ | 1 | 张三 | 1 | | 2 | 张三 | 1 | | 3 | 李四 | 1 | | 4 | 王五 | 2 | | 5 | _王五 | 2 | | 6 | NULL | 2 | | 7 | 赵六 | 3 | +------------+--------------+--------------+ 7 rows in set mysql> select student_name,java_teacher,count(*) from student_table # 要求java_teacher,student_name这两列的值都相同的记录作为一组 group by java_teacher,student_name; +--------------+--------------+----------+ | student_name | java_teacher | count(*) | +--------------+--------------+----------+ | 张三 | 1 | 2 | | 李四 | 1 | 1 | | NULL | 2 | 1 | | _王五 | 2 | 1 | | 王五 | 2 | 1 | | 赵六 | 3 | 1 | +--------------+--------------+----------+ 6 rows in set
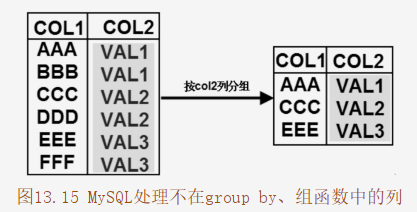
处理不在group by以及组函数中的列 对于很多数据库而言,分组计算时有严格的规则——如果查询列表中使用了组函数,或者select语句中使用了group by分组子句,则要求出现在select列表中的字段,要么使用组函数包起来,要么必须出现在group by子句中。这条规则很容易理解,因为一旦使用了组函数或使用了group by子句,都将导致多条记录只有一条输出 ,系统无法确定输出多条记录中的哪一条记录。MySQL来说,并没有上面的规则要求,如果某个数据列既没有出现在group by之后,也没有使用组函数包起来,则MySQL会输出该列的第一条记录的值。图13.15显示了MySQL的处理结果。
1 2 3 4 5 6 select student_name,java_teacher,count (java_teacher)from student_tablegroup by java_teacher;
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 mysql> select * from student_table; +------------+--------------+--------------+ | student_id | student_name | java_teacher | +------------+--------------+--------------+ | 1 | 张三 | 1 | | 2 | 张三 | 1 | | 3 | 李四 | 1 | | 4 | 王五 | 2 | | 5 | _王五 | 2 | | 6 | NULL | 2 | | 7 | 赵六 | 3 | +------------+--------------+--------------+ 7 rows in set mysql> # student_name这列没有出现在group by子句中, # 也没有出现在分组函数count之中, # MySQL将显示遇到的第一条记录时student_name的值。 select student_name,java_teacher,count(java_teacher) from student_table group by java_teacher; +--------------+--------------+---------------------+ | student_name | java_teacher | count(java_teacher) | +--------------+--------------+---------------------+ | 张三 | 1 | 3 | | 王五 | 2 | 3 | | 赵六 | 3 | 1 | +--------------+--------------+---------------------+ 3 rows in set
having子句 如果需要对分组进行过滤 ,则应该使用having子句,having子句后面也是一个条件表达式,只有满足该条件表达式的分组才会被选出来。having子句和where子句非常容易混淆,它们都有过滤功能,但它们有如下区别。
不能在where子句中过滤组,where子句仅用于过滤行。过滤组必须使用having子句。
不能在where子句中使用组函数,having子句才可使用组函数。
如下SQL语句所示:
1 2 3 4 select java_teacher,count (*)from student_tablegroup by java_teacherhaving count (*)>2 ;
查询结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 mysql> select * from student_table; +------------+--------------+--------------+ | student_id | student_name | java_teacher | +------------+--------------+--------------+ | 1 | 张三 | 1 | | 2 | 张三 | 1 | | 3 | 李四 | 1 | | 4 | 王五 | 2 | | 5 | _王五 | 2 | | 6 | NULL | 2 | | 7 | 赵六 | 3 | +------------+--------------+--------------+ 7 rows in set mysql> select java_teacher,count(*) from student_table group by java_teacher having count(*)>2 ; +--------------+----------+ | java_teacher | count(*) | +--------------+----------+ | 1 | 3 | | 2 | 3 | +--------------+----------+ 2 rows in set
原文链接: 13.2.11 分组和组函数